본 콘텐츠는 사용자의 편의를 고려해 자동 기계 번역 서비스를 사용하였습니다. 영어 원문과 다른 오류, 누락 또는 해석상의 미묘한 차이가 포함될 수 있습니다. 필요하시다면 영어 원문을 참조하시기를 바랍니다.
2년 전 Cloudflare에서는 방대한 3D V-Cache를 갖춘 AMD EPYC™ Genoa-X 프로세서를 기반으로 하는 12세대 서버 제품군을 배포했습니다. 이러한 캐시가 많이 사용되는 아키텍처는 당시의 요청 처리 계층(FL1)에 완벽하게 맞았습니다. 하지만 차세대 하드웨어를 평가하면서 저희는 딜레마에 직면했습니다. 처리량이 가장 많이 향상되는 CPU에는 상당한 캐시 감소가 제공된다는 점이었습니다. 당사의 레거시 소프트웨어 스택은 이러한 목적으로 최적화되어 있지 않았으며, 대기 시간 증가로 인해 잠재적 처리량 이점이 제한되고 있었습니다.
이 블로그에서는 Cloudflare의 핵심 요청 처리 계층을 Rust 기반으로 재작성한 FL2 transition을 통해 Gen 13의 잠재력을 최대한 입증하고 이전 스택에서는 불가능했을 성능 향상을 실현할 수 있었는지 설명합니다. FL2는 용량이 큰 캐시에 대한 의존을 제거하여, SLA를 유지하면서 코어와 함께 성능을 확장할 수 있도록 합니다. 오늘 FL2를 실행하는 AMD EPYC™ 5세대 토리노 기반 서버에 기반한 Cloudflare의 Gen 13을 출시하게 되어 자랑스럽게 생각하며, 에지에서 성능을 효과적으로 캡처하고 확장합니다.
AMD EPYCurin이 테이블에 제공하는 기능
AMD의 EPYC™ 5세대 튜린 기반 프로세서 는 단순히 코어 수 증가 그 이상을 제공합니다. 이러한 아키텍처 덕분에 Cloudflare 서버에 필요한 모든 것을 여러 차원에 걸쳐 개선할 수 있습니다.
2배 코어 수: 12세대의 코어 96개 대비 최대 192개 코어, SMT는 384개 스레드
IPC 개선: 아키텍처가 개선된 Zen 5는 Zen 4에 비해 사이클당 명령이 더 우수합니다
더 나은 전력 효율성: 토리노는 코어 수가 더 많음에도 불구하고 Genoa-X에 비해 코어당 소비 와트가 최대 32% 적습니다
DDR5-6400 지원: 모든 코어에 공급할 수 있는 더 높은 메모리 대역폭
하지만 토리노의 고밀도 OPN에는 코어당 캐시보다 처리량이 우선순위가 높은 의도적으로 타협해야 합니다. Cloudflare의 토리노 스택에 대한 분석에서는 이러한 변화가 두드러지게 나타났습니다. 예를 들어, 최고 밀도의 토리노 OPN을 당사의 12세대 Genoa-X 프로세서와 비교하면 토리노의 192개 코어가 384MB의 L3 캐시를 공유하는 것을 알 수 있습니다. 따라서 각 코어는 12세대 할당의 6분의 1에 해당하는 2MB만 액세스할 수 있습니다. 우리의 경우처럼 캐시 지역성에 크게 의존하는 모든 워크로드의 경우 이러한 감소는 심각한 문제를 야기했습니다.
세대 | 프로세서 | 코어/스 레드 | L3 캐시/코어 |
12세대 | AMD Genoa-X 9684X | 96C/192T | 12MB(3D V-캐시) |
13세대 옵션 1 | AMD Turin 9755 | 128C/256T | 4MB |
13세대 옵션 2 | AMD Turin 9845 | 160C/320T | 2MB |
13세대 옵션 3 | AMD Turin 9965 | 192C/384T | 2MB |
Cloudflare의 FL1 요청 처리 계층인 NGINX 및 LuaJIT 기반 코드의 경우 이러한 캐시 감소가 큰 문제였습니다. 하지만 문제가 될 것이라고 가정만 하지는 않았습니다. 우리는 그것을 측정했습니다.
13세대 CPU 평가 단계에서 저희는 AMD uProf 도구를 사용하여 CPU 성능 카운터와 프로파일링 데이터를 수집하여 내부에서 무슨 일이 일어나고 있는지 정확히 파악했습니다. 데이터 결과:
3D V 캐시 프로세서가 탑재된 12세대 서버에 비해 L3 캐시 누락률이 크게 증가했습니다
이전에 L3에 머물던 데이터가 이제 D램으로 이동해야 하므로 메모리 가져오기 대기 시간이 요청 처리 시간에 지배적임
Cloudflare에서는 CPU 사용량을 높게 조정하고 캐시 경합이 악화되었으므로 대기 시간 페널티는 가동률에 따라 확장되었습니다
L3 캐시 적중은 약 50주기 내에 완료됩니다. D램 액세스가 필요한 L3 캐시 누락에는 350 사이클 이상이 걸리며, 이는 엄청난 차이입니다. 코어당 캐시가 6배 감소한 13세대의 FL1은 훨씬 더 자주 메모리를 공격했고, 이로 인해 대기 시간 페널티가 발생했습니다.
13세대에서 FL1을 실행한 초기 테스트에서 성능 카운터가 이미 제안한 사항이 확인되었습니다. 토리노 프로세서의 경우 더 높은 처리량을 달성할 수 있었지만, 대기 시간 비용이 급격했습니다.
메트릭 | 12세대(FL1) | 13세대 - AMD Turin 9755 (FL1) | 13세대 - AMD Turin 9845 (FL1) | 13세대 - AMD Turin 9965(FL1) | Delta |
코어 수 | 기준선 | +33% | +67% | +100% | |
플로리다주 처리량 | 기준선 | +10% | +31% | +62% | 개선 |
CPU 사용률이 낮거나 보통인 경우의 대기 시간 | 기준선 | +10% | +30% | +30% | 회귀 |
높은 CPU 활용도에서의 대기 시간 | 기준선 | > 20% | > 50% | > 50% | 허용되지 않음 |
60%의 처리량 향상을 달성한 AMD Turin 9965를 탑재한 Gen 13 평가 서버는 매우 매력적이었고, 성능이 향상되어 Cloudflare의 총소유비용(TCO)이 가장 많이 개선되었습니다.
하지만 대기 시간이 50%를 초과하는 것은 허용되지 않습니다. 요청 처리 대기 시간의 증가는 고객 경험에 직접적인 영향을 미칩니다. 저희는 익숙한 인프라 문제에 직면했습니다. TCO 이점이 없는 솔루션을 수락할까요? 아니면 늘어난 대기 시간을 감수할 것인가, 아니면 대기 시간을 늘리지 않고 효율성을 높이는 방법을 찾아야 할까요?
최적의 결과를 위한 경로를 찾기 위해 저희는 AMD와 협력하여 Turin 9965 데이터를 분석하고 표적화된 최적화 실험을 진행했습니다. 우리는 체계적으로 여러 구성을 테스트했습니다.
하드웨어 조정: 하드웨어 프리페처 및 Data Fabric(DF) 프로브 필터의 조정으로, 미미한 이득만 보임
Workers 확장: 더 많은 FL1 Workers를 출시하여 처리량은 개선되었지만, 다른 프로덕션 서비스로부터 리소스를 잠식함
CPU 피닝 & 격리: 워크로드 격리 구성을 조정하여 최적의 조합 찾기, 하지만 성공은 제한적
궁극적으로 가장 큰 가치를 제공한 구성은 AMD의 플랫폼 서비스 품질(PQOS)이었습니다. PQOS 확장을 사용하면 캐시 및 메모리 대역폭과 같은 공유 리소스를 세밀하게 조정할 수 있습니다. 토리노 프로세서는 1개의 I/O 다이와 최대 12개의 코어 복합 다이(CCD)로 구성되어 있으며, 각각 최대 16개의 코어에서 L3 캐시를 공유하므로 이를 테스트하기 위한 과정입니다. 다양한 실험 구성의 성과는 다음과 같습니다.
첫째, 우리는 PQOS를 사용하여 FL1에 대해 단일 CCD 내에서 전용 L3 캐시 공유를 할당했습니다. 하지만 이 개념을 소켓 수준으로 확장하고 전체 CCD를 FL1에만 할당했을 때 대기 시간은 허용할 만한 수준으로 유지한 채 처리량도 유의미하게 향상되었습니다.
|
구성
|
설명
|
일러스트레이션
|
성능 향상
|
|
NUMA 인식 코어 선호도
(소켓 수준의 PQOS와 동일)
|
12개의 CCD 중 6개(numa 도메인과 일치)가 FL을 실행합니다.
모든 코어에서 공유되는 각 CCD의 32MB L3 캐시.
|
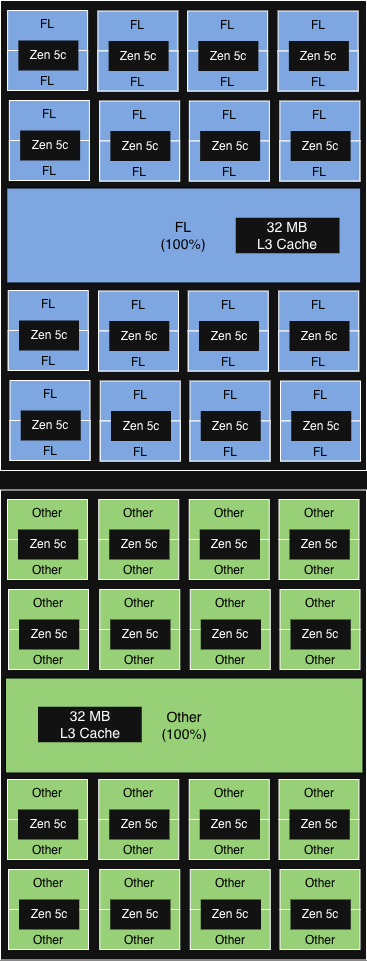
|
>15% 증분
처리량 향상
|
|
PQOS 구성 1
|
각 물리적 코어에 있는 2개의 vCPU 중 1개 CCD에서 FL 실행.
FL은 각 CCD의 32MB L3 캐시의 75%를 차지합니다.
|
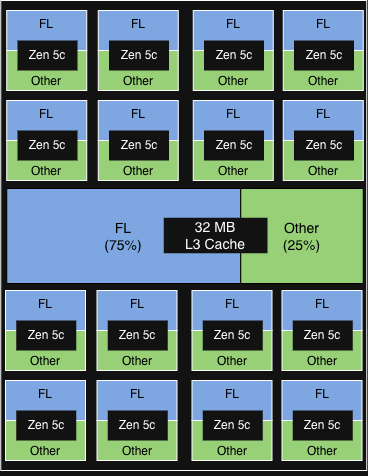
|
< 5% 증분 처리량 향상
기타 서비스는 경미한 성능 저하의 징후를 보임
|
|
PQOS 구성 2
|
vCPU 2개 중 1개 각 CCD의 물리적 코어에 있는 1개가 작동합니다.
FL은 각 CCD의 32MB L3 캐시의 50%를 차지합니다.
|
|
< 5% 증분 처리량 향상
|
|
PQOS 구성 3
|
2개의 vCPU(각 CCD에서 물리적 코어의 50%)는 실시간으로 실행됩니다.
FL은 각 CCD의 32MB L3 캐시의 50%를 차지합니다.
|
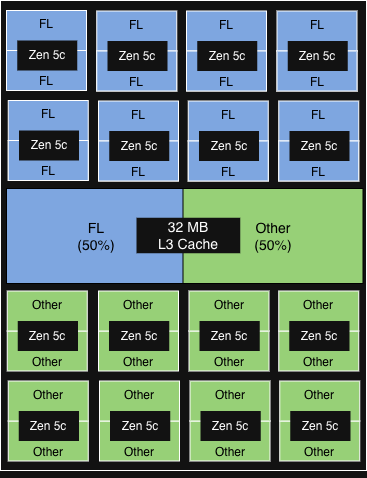
|
< 5% 증분 처리량 향상
|
하드웨어 튜닝과 리소스 구성으로는 소폭의 이익이 제공되었지만, 13세대 아키텍처의 성능 잠재력을 진정으로 활용하려면 소프트웨어 스택을 다시 작성하여 시스템 리소스를 활용하는 방식을 근본적으로 바꾸어야 한다는 것을 알고 있었습니다.
다행히 처음부터 시작하지는 않았습니다. 2025년 창립기념일 주간에서 발표한 바와 같이, Cloudflare는 이미 FL1을 기초부터 재구축하고 있었습니다. FL2는 Pingora 및 Oxy 프레임워크를 기반으로 구축된 Rust의 요청 처리 계층을 완전히 재작성하여 15년간 사용된 NGINX 및 LuaJIT 코드를 대체합니다.
FL2 프로젝트는 13세대 캐시 문제를 해결하려고 시작된 것이 아닙니다. 더 나은 보안(Rust의 메모리 안전성), 더 빠른 개발 속도(엄격한 모듈 시스템), 전반적으로 향상된 성능(더 적은 CPU, 더 적은 모듈식 실행).
메모리 액세스 패턴이 더 개선되고 동적 할당이 덜한 깔끔한 FL2의 아키텍처는 FL1처럼 대규모 L3 캐시에 의존하지 않을 수 있습니다. 이를 통해 FL2 전환을 사용하여 13세대의 처리량 향상을 대기 시간 페널티 없이 실현할 수 있는지 여부를 증명할 수 있는 기회가 되었습니다.
FL2 롤아웃이 진행되면서 13세대 서버의 프로덕션 지표가 가설을 입증했습니다.
메트릭 | 13세대 AMD Turin 9965(FL1) | 13세대 AMD Turin 9965(FL2) |
CPU당 FL 요청% | 기준선 | 50% 이상 |
대기 시간과 12세대 비교 | 기준선 | 70% 감소 |
처리량과 12세대 비교 | 62% 이상 | 100% 이상 |
새로운 FL2 스택에서는 시스템 최적화 전에도 즉시 사용 가능한 효율성 향상이 막대했습니다. FL2는 대기 시간 페널티를 70% 줄임으로써 대기 시간 SLA를 엄격하게 준수하면서 13세대의 CPU 사용률을 높일 수 있었습니다. FL1이 없었다면 이는 불가능했을 것입니다.
FL2는 캐시 병목 현상을 효과적으로 제거함으로써 코어 수에 따라 처리량을 선형적으로 확장할 수 있습니다. 고밀도 AMD Turin 9965가 그 영향을 미친 것은 부인할 수 없습니다. 우리는 성능을 2배 개선하여 하드웨어의 진정한 잠재력을 실현했습니다. 시스템을 추가로 조정하면 13세대 제품군에서 더 많은 전력을 끌어낼 수 있을 것으로 예상됩니다.
코어 수가 많은 AMD Turin 9965의 엄청난 처리량을 선사하는 FL2를 통해, Cloudflare는 13세대 배포를 위해 이 프로세서들을 공식적으로 선택했습니다. 하드웨어 검증이 완료되었으며, 이제 13세대 서버가 글로벌 롤아웃을 지원할 수 있는 대규모로 출시되고 있습니다.
| 12세대 | 13세대 |
프로세서 | AMD EPYC™ 4세대 Genoa-X 9684X | AMD EPYC™ 5세대 Turin 9965 |
코어 수 | 96C/192T | 192C/384T |
플로리다주 처리량 | 기준선 | 최대 +100% |
와트당 성능 | 기준선 | 최대 +50% |
Gen 12 대비 최대 2배 처리량 타협 없는 고객 경험을 위해: 대기 시간 SLA를 유지하면서 처리량을 두 배로 함으로써, Cloudflare에서는 애플리케이션의 빠른 응답성을 보장하고 대규모 트래픽 급증을 흡수할 수 있습니다.
지속 가능한 확장을 위해 12세대 대비 와트당 성능 50% 향상 : 이러한 전력 효율성 향상은 데이터 센터 확장 비용을 절감할 뿐만 아니라 요청당 탄소 발자국을 크게 낮추며 증가하는 트래픽을 처리할 수 있게 합니다.
글로벌 에지 업그레이드의 경우 12세대 대비 60% 랙 처리량: 랙 전력 예산을 일정하게 유지하면서 이러한 처리량 밀도를 달성했기 때문에 Cloudflare는 이 차세대 컴퓨팅을 글로벌 에지 네트워크를 통해 전 세계 모든 곳에 원활하게 배포할 수 있으며, 최고의 성능을 정확히 제공할 수 있습니다 제공할 수 있기 때문입니다.
Cloudflare의 레거시 요청 제공 계층 FL1이 13세대에서 캐시 경합 벽에 부딪혀 처리량과 대기 시간 사이에서 용납할 수 없는 절충안이 발생했습니다. 우리는 기능을 손상시키는 대신 FL2를 구축했습니다.
FL2를 사용하면 메모리 액세스 패턴이 대폭 간소화되며 대규모 L3 캐시에 대한 의존도가 없어지며 코어 수와 선형적으로 비례하여 규모를 확장할 수 있습니다. 13세대 AMD 토리노 플랫폼에서 실행되는 FL2는 SLA 범위 내에서 대기 시간을 유지하면서 2배의 처리량과 50%의 전력 효율성을 제공합니다. 이러한 도약은 하드웨어-소프트웨어 공동 설계의 중요성을 다시 한번 일깨우는 신호탄입니다. 이제 13세대 서버는 캐시 제한의 제약 없이 Cloudflare를 배포하여 Cloudflare의 전역 네트워크에서 수백만 건의 요청을 처리할 준비가 되었습니다.
글로벌 규모의 인프라 개발에 관심이 있으시다면, Cloudflare에서인재를 채용하고 있습니다.