Two years ago, Cloudflare deployed our 12th Generation server fleet, based on AMD EPYC™ Genoa-X processors with their massive 3D V-Cache. That cache-heavy architecture was a perfect match for our request handling layer, FL1 at the time. But as we evaluated next-generation hardware, we faced a dilemma — the CPUs offering the biggest throughput gains came with a significant cache reduction. Our legacy software stack wasn't optimized for this, and the potential throughput benefits were being capped by increasing latency.
This blog describes how the FL2 transition, our Rust-based rewrite of Cloudflare's core request handling layer, allowed us to prove Gen 13's full potential and unlock performance gains that would have been impossible on our previous stack. FL2 removes the dependency on the larger cache, allowing for performance to scale with cores while maintaining our SLAs. Today, we are proud to announce the launch of Cloudflare's Gen 13 based on AMD EPYC™ 5th Gen Turin-based servers running FL2, effectively capturing and scaling performance at the edge.
What AMD EPYCTurin brings to the table
AMD's EPYC™ 5th Generation Turin-based processors deliver more than just a core count increase. The architecture delivers improvements across multiple dimensions of what Cloudflare servers require.
2x core count: up to 192 cores versus Gen 12's 96 cores, with SMT providing 384 threads
Improved IPC: Zen 5's architectural improvements deliver better instructions-per-cycle compared to Zen 4
Better power efficiency: Despite the higher core count, Turin consumes up to 32% fewer watts per core compared to Genoa-X
DDR5-6400 support: Higher memory bandwidth to feed all those cores
However, Turin's high density OPNs make a deliberate tradeoff: prioritizing throughput over per core cache. Our analysis across the Turin stack highlighted this shift. For example, comparing the highest density Turin OPN to our Gen 12 Genoa-X processors reveals that Turin's 192 cores share 384MB of L3 cache. This leaves each core with access to just 2MB, one-sixth of Gen 12's allocation. For any workload that relies heavily on cache locality, which ours did, this reduction posed a serious challenge.
Generation | Processor | Cores/Threads | L3 Cache/Core |
Gen 12 | AMD Genoa-X 9684X | 96C/192T | 12MB (3D V-Cache) |
Gen 13 Option 1 | AMD Turin 9755 | 128C/256T | 4MB |
Gen 13 Option 2 | AMD Turin 9845 | 160C/320T | 2MB |
Gen 13 Option 3 | AMD Turin 9965 | 192C/384T | 2MB |
For our FL1 request handling layer, NGINX- and LuaJIT-based code, this cache reduction presented a significant challenge. But we didn't just assume it would be a problem; we measured it.
During the CPU evaluation phase for Gen 13, we collected CPU performance counters and profiling data to identify exactly what was happening under the hood using AMD uProf tool. The data showed:
L3 cache miss rates increased dramatically compared to Gen 12's server equipped with 3D V-cache processors
Memory fetch latency dominated request processing time as data that previously stayed in L3 now required trips to DRAM
The latency penalty scaled with utilization as we pushed CPU usage higher, and cache contention worsened
L3 cache hits complete in roughly 50 cycles; L3 cache misses requiring DRAM access take 350+ cycles, an order of magnitude difference. With 6x less cache per core, FL1 on Gen 13 was hitting memory far more often, incurring latency penalties.
The tradeoff: latency vs. throughput
Our initial tests running FL1 on Gen 13 confirmed what the performance counters had already suggested. While the Turin processor could achieve higher throughput, it came at a steep latency cost.
Metric | Gen 12 (FL1) | Gen 13 - AMD Turin 9755 (FL1) | Gen 13 - AMD Turin 9845 (FL1) | Gen 13 - AMD Turin 9965 (FL1) | Delta |
Core count | baseline | +33% | +67% | +100% | |
FL throughput | baseline | +10% | +31% | +62% | Improvement |
Latency at low to moderate CPU utilization | baseline | +10% | +30% | +30% | Regression |
Latency at high CPU utilization | baseline | > 20% | > 50% | > 50% | Unacceptable |
The Gen 13 evaluation server with AMD Turin 9965 that generated 60% throughput gain was compelling, and the performance uplift provided the most improvement to Cloudflare’s total cost of ownership (TCO).
But a more than 50% latency penalty is not acceptable. The increase in request processing latency would directly impact customer experience. We faced a familiar infrastructure question: do we accept a solution with no TCO benefit, accept the increased latency tradeoff, or find a way to boost efficiency without adding latency?
To find a path to an optimal outcome, we collaborated with AMD to analyze the Turin 9965 data and run targeted optimization experiments. We systematically tested multiple configurations:
Hardware Tuning: Adjusting hardware prefetchers and Data Fabric (DF) Probe Filters, which showed only marginal gains
Scaling Workers: Launching more FL1 workers, which improved throughput but cannibalized resources from other production services
CPU Pinning & Isolation: Adjusting workload isolation configurations to find optimal mix, with limited success
The configuration that ultimately provided the most value was AMD’s Platform Quality of Service (PQOS). PQOS extensions enable fine-grained regulation of shared resources like cache and memory bandwidth. Since Turin processors consist of one I/O Die and up to 12 Core Complex Dies (CCDs), each sharing an L3 cache across up to 16 cores, we put this to the test. Here is how the different experimental configurations performed.
First, we used PQOS to allocate a dedicated L3 cache share within a single CCD for FL1, the gains were minimal. However, when we scaled the concept to the socket level, dedicating an entire CCD strictly to FL1, we saw meaningful throughput gains while keeping latency acceptable.
|
Configuration
|
Description
|
Illustration
|
Performance gain
|
|
NUMA-aware core affinity
(equivalent to PQOS at socket level)
|
6 out of 12 CCD (aligned with NUMA domain) run FL.
32MB L3 cache in each CCD shared among all cores.
|
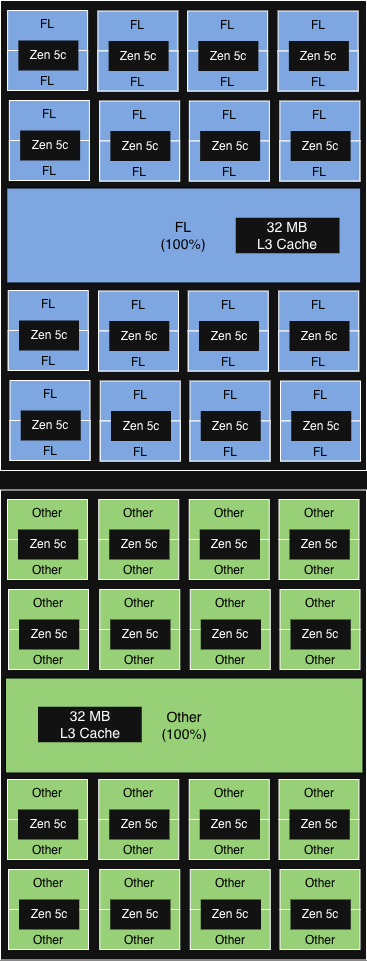
|
>15% incremental
throughput gain
|
|
PQOS config 1
|
1 of 2 vCPU on each physical core in each CCD runs FL.
FL gets 75% of the 32MB L3 cache of each CCD.
|
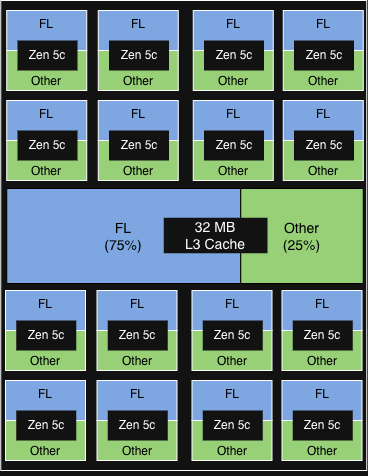
|
< 5% incremental throughput gain
Other services show minor signs of degradation
|
|
PQOS config 2
|
1 of 2 vCPU in each physical core in each CCD runs FL.
FL gets 50% of the 32MB L3 cache of each CCD.
|
|
< 5% incremental throughput gain
|
|
PQOS config 3
|
2 vCPU on 50% of the physical core in each CCD runs FL.
FL gets 50% of the 32MB L3 cache of each CCD.
|
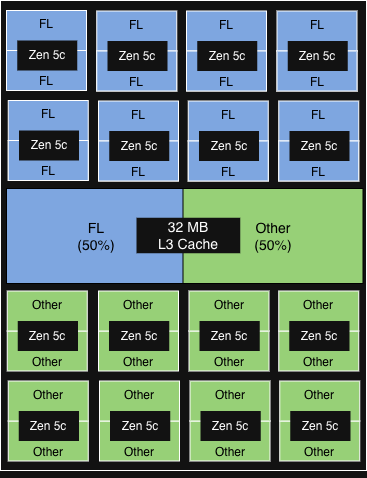
|
< 5% incremental throughput gain
|
The opportunity: FL2 was already in progress
Hardware tuning and resource configuration provided modest gains, but to truly unlock the performance potential of the Gen 13 architecture, we knew we would have to rewrite our software stack to fundamentally change how it utilized system resources.
Fortunately, we weren't starting from scratch. As we announced during Birthday Week 2025, we had already been rebuilding FL1 from the ground up. FL2 is a complete rewrite of our request handling layer in Rust, built on our Pingora and Oxy frameworks, replacing 15 years of NGINX and LuaJIT code.
The FL2 project wasn't initiated to solve the Gen 13 cache problem — it was driven by the need for better security (Rust's memory safety), faster development velocity (strict module system), and improved performance across the board (less CPU, less memory, modular execution).
FL2's cleaner architecture, with better memory access patterns and less dynamic allocation, might not depend on massive L3 caches the way FL1 did. This gave us an opportunity to use the FL2 transition to prove whether Gen 13's throughput gains could be realized without the latency penalty.
Proving it out: FL2 on Gen 13
As the FL2 rollout progressed, production metrics from our Gen 13 servers validated what we had hypothesized.
Metric | Gen 13 AMD Turin 9965 (FL1) | Gen 13 AMD Turin 9965 (FL2) |
FL requests per CPU% | baseline | 50% higher |
Latency vs Gen 12 | baseline | 70% lower |
Throughput vs Gen 12 | 62% higher | 100% higher |
The out-of-the-box efficiency gains on our new FL2 stack were substantial, even before any system optimizations. FL2 slashed the latency penalty by 70%, allowing us to push Gen 13 to higher CPU utilization while strictly meeting our latency SLAs. Under FL1, this would have been impossible.
By effectively eliminating the cache bottleneck, FL2 enables our throughput to scale linearly with core count. The impact is undeniable on the high-density AMD Turin 9965: we achieved a 2x performance gain, unlocking the true potential of the hardware. With further system tuning, we expect to squeeze even more power out of our Gen 13 fleet.
Generational improvement with Gen 13
With FL2 unlocking the immense throughput of the high-core-count AMD Turin 9965, we have officially selected these processors for our Gen 13 deployment. Hardware qualification is complete, and Gen 13 servers are now shipping at scale to support our global rollout.
| Gen 12 | Gen 13 |
Processor | AMD EPYC™ 4th Gen Genoa-X 9684X | AMD EPYC™ 5th Gen Turin 9965 |
Core count | 96C/192T | 192C/384T |
FL throughput | baseline | Up to +100% |
Performance per watt | baseline | Up to +50% |
Up to 2x throughput vs Gen 12 for uncompromising customer experience: By doubling our throughput capacity while staying within our latency SLAs, we guarantee our applications remain fast and responsive, and able to absorb massive traffic spikes.
50% better performance/watt vs Gen 12 for sustainable scaling: This gain in power efficiency not only reduces data center expansion costs, but allows us to process growing traffic with a vastly lower carbon footprint per request.
60% higher rack throughput vs Gen 12 for global edge upgrades: Because we achieved this throughput density while keeping the rack power budget constant, we can seamlessly deploy this next generation compute anywhere in the world across our global edge network, delivering top tier performance exactly where our customers want it.
Gen 13 + FL2: ready for the edge
Our legacy request serving layer FL1 hit a cache contention wall on Gen 13, forcing an unacceptable tradeoff between throughput and latency. Instead of compromising, we built FL2.
Designed with a vastly leaner memory access pattern, FL2 removes our dependency on massive L3 caches and allows linear scaling with core count. Running on the Gen 13 AMD Turin platform, FL2 unlocks 2x the throughput and a 50% boost in power efficiency all while keeping latency within our SLAs. This leap forward is a great reminder of the importance of hardware-software co-design. Unconstrained by cache limits, Gen 13 servers are now ready to be deployed to serve millions of requests across Cloudflare’s global network.
If you're excited about working on infrastructure at global scale, we're hiring.