このコンテンツは自動機械翻訳サービスによる翻訳版であり、皆さまの便宜のために提供しています。原本の英語版と異なる誤り、省略、解釈の微妙な違いが含まれる場合があります。ご不明な点がある場合は、英語版原本をご確認ください。
2年前、Cloudflareは、大規模な3D V-キャッシュを備えたAMD EPYC™ Genoa-Xプロセッサを搭載した第12世代サーバーフリートをデプロイしました。そのキャッシュ重視のアーキテクチャは、当時のリクエスト処理レイヤーであるFL1に完璧にマッチしていました。しかし、次世代ハードウェアを評価した際、ジレンマに直面しました。最大のスループットの向上をもたらすCPUが、大幅なキャッシュ削減を伴うものでした。当社のレガシーソフトウェアスタックはこの点に最適化されておらず、潜在的なスループットの利点は遅延の増加によって膨れ上がっていました。
このブログでは、Cloudflareのコアリクエスト処理レイヤーをRustベースで書き直したFL2への移行によって、Gen 13の可能性を最大限に引き出し、従来のスタックでは不可能だったパフォーマンスの向上をどのように実現したかについて説明します。FL2はより大きなキャッシュへの依存をやめ、SLAを維持しながら、コアによってパフォーマンスを拡張することができます。本日、CloudflareのAMD EPYC™第5世代のTurinベースのサーバーのローンチを発表しました。これは、エッジでのパフォーマンスの向上とスケーリングを効果的に実現します。
AMDのEPYC™第5世代Turinベースプロセッサは、コア数の増加だけではありません。このアーキテクチャは、Cloudflareサーバーが必要とする複数の次元にわたり、改善を実現します。
2倍のコア数:第12世代の96コアと比較して最大192コア、SMTは384スレッドを提供
IPCの向上:Zen 5はアーキテクチャの改善により、Zen 4に比べより良いサイクルあたりの指示を提供
より良い電力効率:コア数は多いにもかかわらず、TurinはGenoa-Xと比較してコアあたりの消費電力が最大32%少ない
DDR5-6400サポート:すべてのコアに供給するための、より高いメモリ帯域幅
しかし、Turinの密度の高いOPNは、コアキャッシュごとのスループットを優先するという意図的なトレードオフを行います。当社のTurinスタック全体の分析では、この変化が浮き彫りになりました。例えば、最も密度の高いTurin OPNと第12世代のGenoa-Xプロセッサを比較すると、Turinの192コアが384MBのL3キャッシュを共有していることがわかります。これにより、各コアはわずか2MB、第12世代の割り当ての6分の1にアクセスできるようになります。当社がしたように、キャッシュの局所性に大きく依存しているワークロードにとって、この減少は深刻な課題となりました。
生成 | プロセッサー | コア/スレッド | L3キャッシュ/コア |
第12世代 | AMD Genoa-X 9684X | 96C/192T | 12MB(3D V-Cache) |
第13世代 オプション1 | AMD Turin 9755 | 128C/2560兆 | 4MB |
第13世代 オプション2 | AMD Turin 9845 | 160C/320T | 2MB |
第13世代 オプション3 | AMD Turin 9965 | 192C/384T | 2MB |
当社のFL1リクエスト処理レイヤー、NGINXベース、LuaJITベースのコードにとって、このキャッシュ削減は大きな課題でした。しかし、私たちはそれが問題になると想定しただけではなく、測定しました。
Gen 13のCPU評価フェーズでは、CPUパフォーマンスカウンターとプロファイリングデータを収集し、AMD uProfツールを使用して、内部で何が起こっているかを正確に特定しました。データは以下を示しました:
L3のキャッシュミス率は、3D Vキャッシュプロセッサを搭載した第12世代のサーバーと比較して劇的に増加しました
以前はL3にあったデータをDRAMへ移す必要があったため、メモリフェッチの遅延がリクエスト処理時間の大半を占めていた
CPU使用率を上げ、キャッシュコンテンツを悪化させると、利用率の上昇による遅延のペナルティが増大
L3のキャッシュヒットは約50サイクルで完了します。 DRAMアクセスを必要とするL3のキャッシュミスは350サイクル以上かかり、その差は歴然としています。コアあたりのキャッシュ容量が6分の1以下の第13世代のFL1は、メモリヒット率がはるかに高くなり、遅延のペナルティが発生していました。
第13世代でFL1を稼働させた初期テストでは、パフォーマンスカウンターがすでに示唆した内容を確認することができました。Turinプロセッサは、より高いスループットを実現できましたが、遅延の費用が嵩みました。
指標 | Gen 12(FL1) | Gen 13 - AMD Turin 9755(FL1) | Gen 13 - AMD Turin 9845(FL1) | Gen 13 - AMD Turin 9965(FL1) | deleteC |
コア数 | ベースライン | +33% | +67% | +100% | |
FLスループット | ベースライン | +10% | +31% | +62% | 改善 |
低から中程度のCPU使用率における遅延 | ベースライン | +10% | +30% | +30% | 回帰 |
CPU使用率が高い場合の遅延 | ベースライン | > 20% | > 50% | > 50% | 容認されない |
60%のスループット向上を実現したAMD Turin 9965の第13世代評価サーバは魅力的なものであり、パフォーマンスの向上はCloudflareの総所有コスト(TCO)に最も改善をもたらしました。
しかし、50%を超える遅延のペナルティは許容されません。リクエスト処理の遅延が増加すると、カスタマーエクスペリエンスに直接影響を与えます。TCOのメリットがないソリューションを受け入れるか、遅延の増加を受け入れるか、あるいは遅延を発生させずに効率を高める方法を見つけるか、といったインフラストラクチャに関するよくある質問に直面しました。
最適な結果への道筋を見つけるために、AMDと協力してTurin 9965のデータを分析し、標的を絞った最適化の実験を行いました。複数の設定を体系的にテストしました。
ハードウェアのチューニング: ハードウェアプリフェッチャーとData Fabric (DF) プローブフィルターを調整しましたが、わずかな向上しか見られませんでした
Scaling Workers:FL1 Workersをさらに起動することでスループットは改善されたが、他の本番サービスからリソースを奪った
CPUピン留め & 分離: ワークロードの分離構成を調整して最適な組み合わせを見つけるが、成果は限定的
最終的に最も価値をもたらした設定は、AMDのPlatform Quality of Service(PQOS)でした。PQOS拡張により、キャッシュやメモリの帯域幅など共有リソースのきめ細やかな制御が可能になります。Turinプロセッサは、1つのI/O抜き図と最大12個のコア・複雑・ダイ(CCD)で構成され、それぞれが最大16個のコアでL3キャッシュを共有するため、これをテストしました。さまざまな実験的構成がどのように行われたかを次に示します。
まず、PQOSを使ってFL1の単一CCD内の専用L3キャッシュシェアを割り当てましたが、効果はごくわずかでした。しかし、概念をソケットレベルに広げ、全体のCCDを厳密にFL1に特化した場合、遅延を許容しながら、スループットが大幅に向上することができました。
|
設定
|
説明
|
イラスト
|
パフォーマンスの向上
|
|
NUMA対応コアアフィニティ
(ソケットレベルでPQOSと同等)
|
12のCCD(NUMAドメインと整合)は6がFLを実行しています。
各CCDの32MB第3キャッシュは、全コアで共有されます。
|
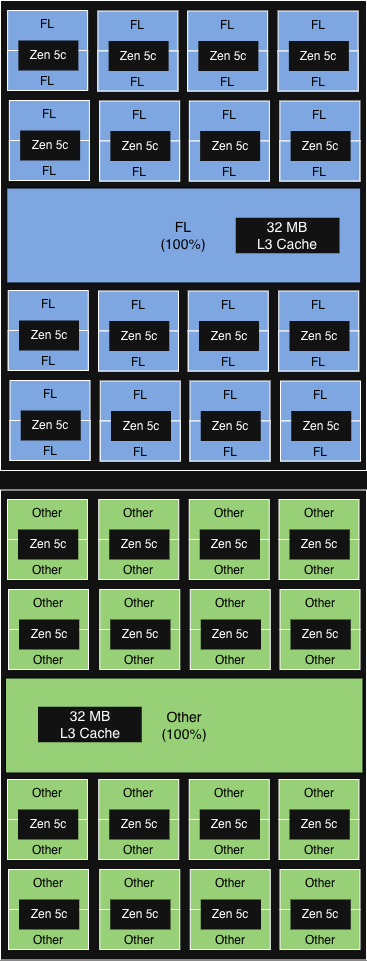
|
>15%増分
スループットの向上
|
|
PQOS設定 1
|
各CCDの各物理コアの2vCPUのうち1つがFLを実行しています。
FLは、各CCDの32MBL3キャッシュの75%を取得します。
|
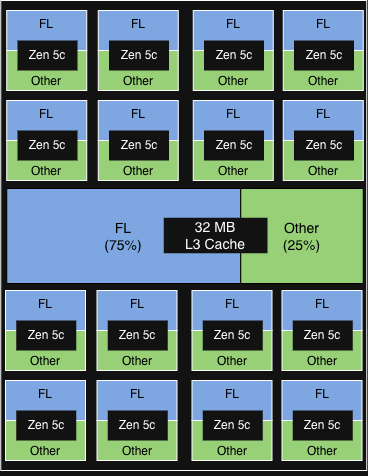
|
スループット増大5%未満
その他のサービスでは、わずかな劣化の兆候が見られる
|
|
PQOS設定 2
|
各CCDの各物理コアの2 vCPUのうち1つがFLを実行しています。
FLは、各CCDの32MBL3キャッシュの50%を取得します。
|
|
スループット増大5%未満
|
|
PQOS設定 3
|
各CCDの物理コアの50%の2 vCPUがFLを実行しています。
FLは、各CCDの32MBL3キャッシュの50%を取得します。
|
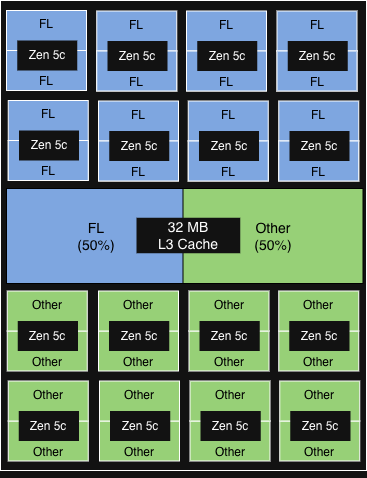
|
スループット増大5%未満
|
ハードウェアのチューニングとリソースの構成によっては控えめな結果も得られましたが、第13世代アーキテクチャのパフォーマンスの可能性を真に引き出すには、ソフトウェアスタックを書き換えてシステムリソースの利用方法を根本的に変える必要があることが分かっていました。
幸いなことに、ゼロから始めるわけではありませんでした。バースデーウィーク2025中に発表したように、すでにFL1をゼロから再構築していました。FL2はRustのリクエスト処理レイヤーを完全に書き換えたもので、PingoraとOxyのフレームワーク上に構築されており、15年にわたるNGINXとLuaJITのコードに置き換えられています。
FL2プロジェクトは第13世代のキャッシュ問題を解決するために始まったわけではなく、より優れたセキュリティ(Rustのメモリ安全性)、開発速度の高速化(厳格なモジュールシステム)、ボード全体的なパフォーマンス改善(CPUを減らす)、メモリ、モジュラー実行など)を作るのです。
FL2のクリーンなアーキテクチャは、優れたメモリアクセスパターンで動的割り当てが少ないため、FL1のように大量のL3キャッシュに依存しないかもしれません。これにより、FL2の移行を使用して、第13世代のスループットの向上が遅延のペナルティなしに実現できるかどうかを証明する機会が得られました。
FL2の展開が進むにつれて、第13世代サーバーからの本番メトリクスで、仮定した内容が検証されることになりました。
指標 | Gen 13 AMD Turin 9965(FL1) | Gen 13 AMD Turin 9965(FL2) |
CPU%あたりのFLリクエスト | ベースライン | 50%高い |
遅延とGen 12 | ベースライン | 70%低い |
スループットとGen 12 | 62%高い | 100%高い |
新しいFL2スタックは、システムの最適化を行う前でも、すぐに大幅な効率向上を実現できました。FL2では遅延のペナルティが70%削減され、遅延SLAを厳密に満たしながら、第13世代のCPU使用率を高めることができるようになりました。FL1の下では、それは不可能だったでしょう。
キャッシュのボトルネックを効果的に解消することで、FL2はコア数に合わせてスループットを直線的に拡張することができます。高密度のAMD Turin 9965に対する影響は否定できません。当社は2倍のパフォーマンス向上を達成し、ハードウェアの真の可能性を引き出しました。さらなるシステムチューニングで、第13世代機器からさらに多くの電力を生み出すことが予想されます。
FL2が高コア数のAMD Turin 9965の膨大なスループットを実現したことで、当社は第13世代展開対象として正式にこれらのプロセッサーを選定しました。ハードウェアの認定が完了し、第13世代サーバーは弊社のグローバルな展開をサポートするために大量に出荷しています。
| 第12世代 | 第13世代 |
プロセッサー | AMD EPYC™ 4th Gen Genoa-X 9684X | AMD EPYC™ 5th Gen Turin 9965 |
コア数 | 96C/192T | 192C/384T |
FLスループット | ベースライン | 最大+100% |
ワットごとのパフォーマンス | ベースライン | 最大+50% |
Gen 12に比べて最大2倍のスループットで妥協のないカスタマーエクスペリエンスを実現:遅延SLAの範囲内に維持しながらスループット容量を倍増することで、アプリケーションの高速性と応答性を維持し、大規模なトラフィックスパイクの吸収が可能であることを保証します。
第12世代と比較してパフォーマンス/ワットが50%向上し、持続可能なスケーリングを実現:この電力効率の向上により、データセンターの拡張コストが削減されるだけでなく、リクエストあたりの二酸化炭素排出量を大幅に削減しながら、増加するトラフィックを処理することが可能になります。
グローバルエッジアップグレードのための第12世代と比較して60%高いラックスループット:ラックの電力バジェットを一定に保ちながら、このスループット密度を実現したため、この次世代コンピューティングを、当社のグローバルエッジネットワーク全体で世界中どこにでもシームレスにデプロイでき、お客様が必要とするまさにその場所で最高レベルのパフォーマンスを提供できます。
レイヤーFL1を提供する当社のレガシーリクエストは、Gen13のキャッシュコンテンツウォールにヒットし、スループットとレイテンシーの間で許容できないトレードオフを余儀なくされました。妥協する代わりに、当社はFL2を構築したのです。
非常に無駄のないメモリアクセスパターンで設計されたFL2は、巨大なL3キャッシュへの依存を解消し、コア数による直線的なスケーリングを可能にします。第13世代AMD Turinプラットフォームで稼働するFL2は、スループットが2倍になり、電力効率が50%向上すると同時に、遅延をSLA内に抑えることができます。この飛躍的な前進は、ハードウェアとソフトウェアの共同設計の重要性を改めて認識するものです。キャッシュ制限に制約なく、第13世代サーバーをデプロイして、Cloudflareのグローバルネットワーク全体で何百万ものリクエストを処理できるようになりました。
もしあなたがグローバル規模でのインフラストラクチャに取り組むことに興奮しているなら、当社は採用中です。